Sat Sep 19 00:55:52 CEST 2020
Dealing with (not so) dead disks
Harddisks drives fail...
... but in different ways.
Sometimes the integrated electronics board of a disk dies. I cannot cope with these failures -- such a an HDD is truly dead for me.
Sometimes, just "a few" disk blocks become unreadable (and/or unwritable).
And if you are lucky, the disk got just reported as bad but is actually fine for use: I have seen a RAID enclosure for 16 disks which liked to complain about various disks but always in the same two slots -- I rather suspect a problem with the backplane. Then there are those disks which were just subjected to unfair work conditions: too hot. Give them enough cool air to breathe and they cooperate nicely again.
Ditching an entire HDD because a few first blocks become unreadable is justified in a production setting where HDDs are cheaper than the labor to deal with a corrupted disk and the associated data loss.
In my lab, though, this is where the fun begins. Can I put HDDs "with known issues" still to some proper use? Of course:
-
Not all of my data is important. I would not shed a tear about a lost mp3 file ripped from one of my CDs.
-
I can forgo the loss of a filesystem backup -- there will be new ones soon enough.
-
Build RAID systems from risky disks -- that's what RAIDs are for, after all.
This article takes a closer look at a faulty 250 GB disk. It was pulled from a RAID-1 system where it was easily replaced. (By a 500 GB disk because that was the smallest size sold at that time.)
Summary: dd(1), awk(1), jqt(1), smartctl(1).
Test setup
Here is my current backlog of disks to check:

These are mostly 3.5" SATA HDDs, mostly fallout from production servers in the company.
Disks which are checked with some hope for an afterlife go here:

These are mostly SCSI disks of various vintages. I have no shortage on 68-pin WIDE-SCSI disks. 80-pin SCA disks and 50-pins "FAST" SCSI are the real treasure items, I need these most for the workstation gear I carry. (It has actually become more and more difficult to find the 50pin disks.)
Testing is most easily done with external drive sockets such as these:

This one takes 3.5" and 2.5" SATA disks (rotating dust or SSDs).
It is attached via eSATA to
fred.marshlabs.gaertner.de, a Core2Duo box running
DragonFlyBSD.
IDE (PATA) disks went mostly out of interest but I would have some IDE-to-USB connector kit for these, too. It's the SCSI drives which cause a bit of pain: these have to be mounted into some computer or enclosure, depending on the interface type.
dd(1)ing through the disk
dd(1) is the swiss army knife to deal with
storage devices of all kinds. It works at the block level and isn't
dependent on the actual data. If vital blocks on the disk have
taken a hit so that your partitioning or filesystem are hosed,
dd is not impacted by that.
In the rest of this article, I move from SI-metric Kilo/Mega/Giga units to 2^10 = 1024-based unit factors throughout. Our disk marketed as "250 GB" is really:
ad10: 239429MB <WDC WD2502ABYS-02B7A0 02.03B03> at ata5-master SATA300
according to dmesg. That 239429MB is just a rounded
value, though. The disk advertises itself to the BIOS with a
geometry of
cylinders=486459 heads=16 sectors/track=63
yielding a total of 490350672 blocks (with 512 bytes), or 251059544064 bytes. This justifies the 250 10^9 marketing GB, but we better see this as "239429 and a bit (2^20) MiB (MebiBytes)" or "almost 234 (2^30) GiB (GibiBytes)".
My first command was simply for reading as many blocks from the disk as possible, starting at the beginning (block 0):
% dd if=/dev/ad10 of=/dev/null
This command supposedly runs through the entire disk
(/dev/ad10) as "input file", reading all blocks and
"copying" them over to Unix' big bit bucket, /dev/null
as output (pseudo) file. In case of a problem with reading a disk
block, it bails out at that point with an error message. In any
case we get informed how many blocks were read/written.
When dd runs, it is silent. On BSD systems, you can
issue a SIGINFO signal to the running process by
hitting Ctrl-T. Dd will respond with the block
position it is currently working on.
Reading just one block at a time is slow. On the first
day, I aborted the dd command after having read
200.000.000 blocks (100 GB) successfully.
On the second day, I picked up reading more blocks where I stopped the day before:
% dd if=/dev/ad10 of=/dev/null skip=200000000
This command stopped with this output:
dd: /dev/ad10: Input/output error
135382768+0 records in
135382768+0 records out
69315977216 bytes transferred in 16899.7 secs (4101616 bytes/sec)
Taking the skipped blocks from yesterday's successful but partial run into account, this translate into:
- The first 200000000 + 135382768 = 335382768 blocks are OK.
- Blocks are numbered and addressed starting at 0.
- Block no. 0 though no. 335382767 are good.
- Block no. 335382768 is unreadable.
I noted that block number down into a simple ascii file and then continued testing, skipping all the 335382768 good and 1 bad block just found:
% dd if=/dev/ad10 of=/dev/null skip=335382769
After just another 1482 good blocks, dd would
detect the next error at block no. 335384251. Note that down, skip
335384251 blocks for the next run, rinse and repeat a few times to
get an initial feeling how errors appear to be distributed. I ended
up with these notes:
200000000
135382768
335382768 blks OK.
335382768 bad
335384251 bad
335402546 bad
335404029 bad
335408476 bad
335449276 bad
335450759 bad
335452242 bad
335453724 bad
335455208 bad
I finished with these manual stop-and-go tests at this point and had a look at the distances from one bad block to the next:
% awk '/bad/ {if (old) print $1-old; old=$1}' ad10-hd.errs
1483
18295
1483
4447
40800
1483
1483
1482
1484
There's some pattern here: if something bad happened to the magnetic coating in none place, we should see the same sector destroyed along a series of neighbored tracks. Perhaps 1483 is the physical track length at this spot, or the sum of the track length's across all disk surfaces. Perhaps a surface defect in a single spot would look like this?
For further bad block detection, I let dd do the
job: the conv=noerror will note every problem but
automatically advance past the troubling block (just like we did
before) and continue from there, until the end of the disk. I used
an initial skip to shortly before the first error already found,
block number 335382768:
% dd if=/dev/ad10 of=/dev/null skip=335000000 conv=noerror |& tee ~/ad10-disk.errs
The resulting output starts like this:
dd: /dev/ad10: Input/output error
382768+0 records in
382768+0 records out
195977216 bytes transferred in 26.313414 secs (7447807 bytes/sec)
dd: /dev/ad10: Input/output error
dd: /dev/ad10: Input/output error
384250+0 records in
384250+0 records out
196736000 bytes transferred in 28.703818 secs (6854001 bytes/sec)
dd: /dev/ad10: Input/output error
dd: /dev/ad10: Input/output error
402544+0 records in
402544+0 records out
206102528 bytes transferred in 32.030519 secs (6434567 bytes/sec)
dd: /dev/ad10: Input/output error
dd: /dev/ad10: Input/output error
404026+0 records in
404026+0 records out
206861312 bytes transferred in 34.588290 secs (5980675 bytes/sec)
dd: /dev/ad10: Input/output error
and continues in this style for another 1500 lines. If you look closely, you'll notice the offset-adjusted "records in" numbers increasingly deviate from the bad block numbers established manually:
335382768 335384251 335402546 335404029 ...
335382768 335384250 335402544 335404026 ...
This is because the bad, skipped blocks are not counted as input
records. Lesson learned: conv=sync,noerror would
replace the unreadable blocks with zeroed blocks for the
destination and include these blocks in the the "records in/out"
counts.
We will fix this up when extracting the numbers with
awk below.
I aborted the run after 13910434 blocks before shutting down the
machine and going to bed. The next day, I picked things up at
skip=485000000, finding no further errors on the
disk.
The results
So these runs located 309 errors on the disk:
% awk '/records in$/ {print $1+bad++}' ~/ad10-disk.errs > ad10.bb
% pr -t5 ad10.bb
335382768 335789372 336188550 336561556 337125282
335384251 335790855 336190033 336561768 337126698
335402546 335792337 336191515 336563251 337129770
335404029 335793820 336197446 336566256 337131186
335408476 335795302 336200663 336566468 337132602
335449276 335798520 336205111 336567739 337134018
335450759 335804450 336206593 336567951 337142754
335452242 335805933 336208076 336569221 337199178
335453724 335807415 336214259 336569433 337200594
335455208 335812115 336215741 336570704 337455984
335458424 335813598 336226371 336570916 337458816
335459907 335815080 336227854 336572186 337473216
335461389 335822745 336229337 336572398 337484784
335462872 335831641 336230819 336573669 337487616
335464354 335860568 336232302 336573881 337497768
335465837 335880093 336238484 336575364 337499184
335469054 335887758 336239967 336739950 337503672
335470537 335892207 336241449 336741432 337507920
335472020 335896906 336250597 336742915 337509336
335473502 335898389 336252080 336744397 337510752
335474985 335899871 336253562 336747363 337513824
335476467 335901354 336496544 336753545 337515240
335477950 335902836 336498027 336755028 348457280
335481167 335904320 336504208 336757993 348796478
335482650 335907536 336513105 337054458 348797894
335484132 335909019 336513317 337057290 348800966
335485615 335910502 336514799 337058706 348802382
335487098 335911984 336517805 337061778 348805214
335488580 335913467 336518017 337063194 348806630
335490063 335914949 336522252 337066026 348808046
335494763 335918167 336522464 337068858 348809462
335496245 335919649 336525217 337073346 348812534
335497728 335921132 336525429 337074762 348813950
335499210 335922614 336526912 337076178 348815366
335500693 335924097 336528434 337077594 348816782
335502176 335925580 336529917 337080426 348818198
335505393 335927062 336530129 337081842 348821030
335506876 335930279 336534365 337084914 348829766
335508358 335930280 336534577 337086330 348831182
335509841 335931761 336535848 337087746 348832598
335511323 335931762 336536060 337089162 348837086
335512806 336094401 336537330 337090578 348838502
335514288 336095883 336537542 337091994 348842750
335517506 336133916 336542030 337093410 348844166
335518988 336135399 336542242 337096482 348847238
335520471 336156659 336543513 337097898 348848654
335521954 336158142 336543725 337099314 348850070
335523436 336159625 336544995 337100730 348852902
335532584 336164325 336545207 337102146 348854318
335541732 336165807 336546478 337103562 348857390
335543214 336167290 336546690 337104978 348858806
335553844 336168772 336547961 337108050 348860222
335771077 336170255 336548173 337109466 348861638
335772560 336171737 336552661 337110882 348864470
335775777 336173220 336554143 337112298 348871790
335777259 336176437 336554355 337113714 348873206
335778742 336177920 336555626 337115130 348874622
335780224 336179403 336555838 337118202 348876038
335781707 336180885 336557108 337119618 348877454
335783189 336182368 336557320 337121034 348883358
335784673 336183850 336558591 337122450 348910742
335787889 336185333 336558803 337123866
And here is a plot. The x-axis is along the trouble spots,
y-axis the faulty block number. I added the blocks 0
and 490350671 for the first and last block of the disk
to put the error positions in relation to the whole disk:
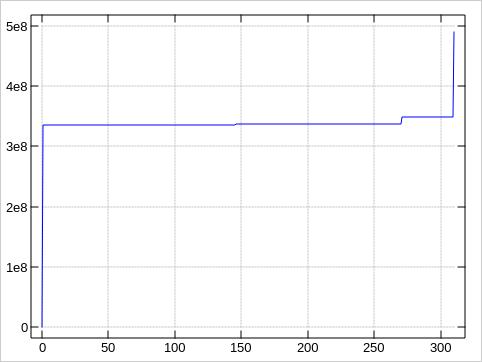
So the first 270 bad blocks cluster in one area, the last 40 ones in another.
Entire faulty range: 335382768 to 348910742 = 13527974 blocks = 6.45 GB
Inner good gap: 337515240 to 348457280 = 10942040 blocks = 5.22 GB
Recovering from bad blocks
With 490.350.672 blocks on our 233 GB disk, we should not get mad if one block gets bad. Bad blocks are just a fact of life.
It would sure be nice that this does not go unnotice. Then again: the system should not panic right away due to a bad black. Disk drives are using checksums and error correction internally to prevent wrong bits being returned to the system. Bits can get flipped at many points though, and filesystems such as ZFS or btrfs will do thier checksums to guard against these things.
Even brand new disks will have bad blocks, and more will evolve with time. It wouldn't be economical for a vendor (or buyer) to bet on "perfect" disks.
There are several methods to handle bad blocks:
-
Sometimes, simply rewriting a bad block can unwedge it again. You have lost the data, of course.
-
Let the disk designate the bad blocks.
Digital Equipment Corporation ("DEC") formulated a standard numbered 144 for their system RK06/RK07 disks. The 144 standard describes how bad blocks are marked as bad. Both the drive controller and the OS can then avoid the blocks where the magic pixie dust has fallen off. The standard is designed to cope with up to 126 bad blocks. Tools such as
bad144(8)let you investigate the current list of bad blocks and mark more blocks as bad.The technology is not dead. Modern drives will do their best to hide such issues from your eyes, too. Disk drives usually come with spare blocks not advertised to the system. The internal drive controller will automatically remap blocks gone bad into spare blocks if possible.
-
Let the filesystem mask out the bad blocks.
For a BSD filesystem,
badsect(8)can prevent bad blocks from being used for regular files. For linux ext2/3/4 filesystems, there isbladblocks(8). -
Partioning around the fault
Use fdisk/gpt/... to prevent suspicious, large areas from being used.
Repartitioning is what I am going to do here. I will define the 7.15 GB from, say, block 335000000 to 349999999 as a "bad" partition, and the space before and after that is still good for healthy partitions. I won't micro-manage he disk by dealing with the good gap within the two bad streaks differently. I would rather play it safe and include more leading/trailing space with the known to be bad area. 20 GB should be plenty to play it safe and yet have much of the disk for continued use.
Saving time -- using larger blocksizes.
Scanning a disk block by block gives you detailed information where the errors are but is very slow. This is why I spent 3 days on this 233 GB disk.
We can significantly speed up things by reading many blocks at time, i.e. tackle the disk with a much larger blocksize option. Here are the first and second GB read from the disk, once transfered in single blocks, and once with 2024 blocks aggregated into a 1 MB transfer size. We read different GBs from the disk to avoid cache effects:
% dd if=/dev/ad10 of=/dev/null bs=1b count=2097152
2097152+0 records in
2097152+0 records out
1073741824 bytes transferred in 134.774307 secs (7966962 bytes/sec)
% dd if=/dev/ad10 of=/dev/null bs=1m skip=1024 count=1024
1024+0 records in
1024+0 records out
1073741824 bytes transferred in 9.100007 secs (117993515 bytes/sec)
Whoa! From 7.6 MB/s to 112.5 MB/s! Warp factor 15! It turns out that even a modest blocksize such as 16 KB gives me 112.2 MB/s throughput.
The maximum throughput is limited by the bottleneck in the chain of
- disk drive performance...
- speed of the SATA/SCSI/FCAL/... bus connecting the disk to the controller.
- speed of the PCI/PCIe/VesaLocal/... bus connecting the controller towards the CPU,
- whatever busses any South/North bridges bring with them,
- ...your CPU.
Exercise for you:
What
ddspeed can you achieve with your disk? Is it related to any marketing number you are expecting from your system? (For example: "SATA-II -- 3 Gbit/s!")
Using a sensible aggregated blocksize, we can map out the 233 GB disk in a mere 40 minutes. Any chunk flagged as unreadable can then be subjected to fine-grained, block-wise analysis.
My first attempts turned out to be miserable failures, though:
Using bs=1g first and then bs=256m, I
caused the machine to
- have I/O failures with the system disk,
- have I/O errors with the network interface (just used for ssh),
- lock up the entire system, requiring the reset button.
I blame the OS for this, DragonFlyBSD-5.8.1 in this case. I
finallly got lucky with bs=1m.
dd if=/dev/ad10 of=/dev/null conv=noerror bs=1m | & tee ad10-1m.dd
created a listing with 175 faults, and these were accompanied by
175 messages from the kernel in /var/log/messages:
Sep 18 16:33:06 fred kernel: ad10: FAILURE - READ_DMA48 status=51<READY,DSC,ERROR> error=40<UNCORRECTABLE> LBA=335382528
Sep 18 16:33:08 fred kernel: ad10: FAILURE - READ_DMA48 status=51<READY,DSC,ERROR> error=40<UNCORRECTABLE> LBA=335402496
Sep 18 16:33:11 fred kernel: ad10: FAILURE - READ_DMA48 status=51<READY,DSC,ERROR> error=40<UNCORRECTABLE> LBA=335408384
[...]
The plots about the error distributions look very much like the first plot, of course:
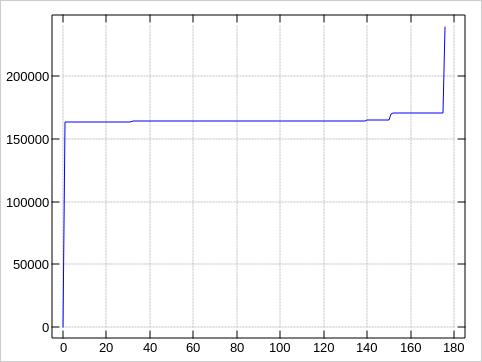
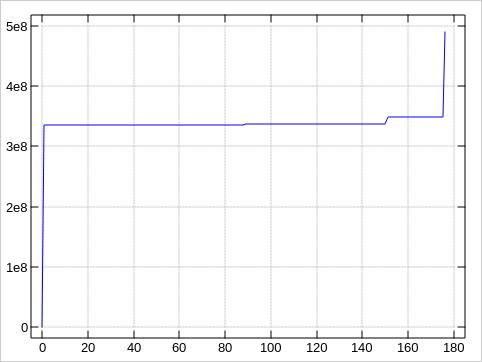
These plots were made by awking the block numbers
from the logs and plotting them with with the jqt IDE
for the j interactive proramming language. J is
very handy to juggle around with data. I used it all the
time for this article, mostly as a calculator for dealing with the
various values and units, for example turning bytes/sec into
MB/s.
If you are stuck with a text terminal, have a look at
ministat(1). This is part of the FreeBSD/DragonFlyBSD
base system and will give you a simple ascii rendition how values
are distributed.
Because our 175 values stack up in just to tall peaks, ending up
in some 130 rows with te default ministat output, let
me sample down the data to just every 10th value for compactness,
and provide the first/last (good) blocks to put the bad block
locations into context:
% printf %d\\n 0 0 239429 239429 > bounds
% awk '0==NR%10' bad-1m > bad-samples
% wc -l bad-samples
17 bad-samples
% ministat -s -w 65 bounds bad-samples
x bounds
+ bad-samples
+---------------------------------------------------------------+
| + |
| + |
| + |
| + |
| + |
| + |
| + |
| + |
| + |
| + |
| + |
| + |
| + |
| x ++ x |
| x ++ x |
||______________________________A______________________________||
| A| |
+---------------------------------------------------------------+
N Min Max Median Avg Stddev
x 4 0 239429 119714.5 119714.5 138234.4
+ 17 163796 170278 164278 164922 2035.2878
No difference proven at 95.0% confidence
Beyond dd - be SMART!
The dd command is transferring the data from the
disk drive across the busses into memory -- just to
/dev/null it there.
Modern disks support the SMART feature. You can ask the drive to do self-tests internally, without impacting the I/O system of the computer.
How this is used shall be part of another article, though.